Thoughts on building marketing & growth capabilities

Adding additional site speed metrics to Google Analytics: measuring First Input Delay (FID)
Web Analytics is still one of my pet peeves, and while I don’t get to spend a ton of time on it anymore these days, I still enjoy digging through blog posts and coming up with new ideas on what to track and how it can help for (speed) optimization. While I was looking through […]

Diversifying Channels for Actual Growth
I’ve worked with many companies who’ve shown exceptional growth, triple digits year over year that brings them to the next levels in their industries (music, education, marketplaces, etc.). But… in some cases, it wasn’t as good as it should have been. Because the main channels that they were using were vastly too big for what […]

Onboarding Marketers: What do you need to know or do in Month 1?
Recruiting, Hiring and building out marketing teams has been what I’ve focused on for the last years. While starting at RVshare in June 2018, my latest role, I wanted to have an impact right away and read into how to best onboard myself in a new environment. But it was also important to provide a […]
Love and/or Hate?! – SEOs & Developers
“I hate my developers,” “We deployed the wrong thing(s),” “Somebody put up a Disallow in my robots.txt that wasn’t meant to be there,” “The whole site is deindexed.” These are just some of the quotes that I’ve heard over the years on the relation between developers/engineers. Where usually, the developers are the ones that receive […]

What books am I reading in 2019?
Update March 2019: I’ve gone through a lot of the books rather quickly this year, that’s why I’ve added a couple of other books that I’d like to read to the bottom of the list. For the last years, I wrote blog posts (2018, 2017 & 2016) listing the books that I read in the […]

Specializing as an SEO – Growing as an SEO (4/4)
The previous three blog posts in this series talked about writing better job descriptions for SEO roles and levels and seniority for SEOs but also but growing on a more personal level. In the last blog post in this series, I want to talk about either being a generalist or specializing as an SEO. But […]

Growing as an SEO (3/4) – Training & Personal Development for SEOs
The previous two blog posts in this series talked about writing better job descriptions for SEO roles and levels and seniority for SEOs. In this blog post, I want to mostly talk about how to grow as an SEO: the fundamental part of this series, how do you get better, what do you grow in, […]

Growing as an SEO (2/4) – Levels & Seniority in SEO Roles
Since I’ve joined RVshare, I needed to think a lot about these questions (again): what people do I need to hire? What experience level do they need to be at? This made me reflect back on hiring for my teams at Postmates and The Next Web and my views on different levels in certain functions. […]
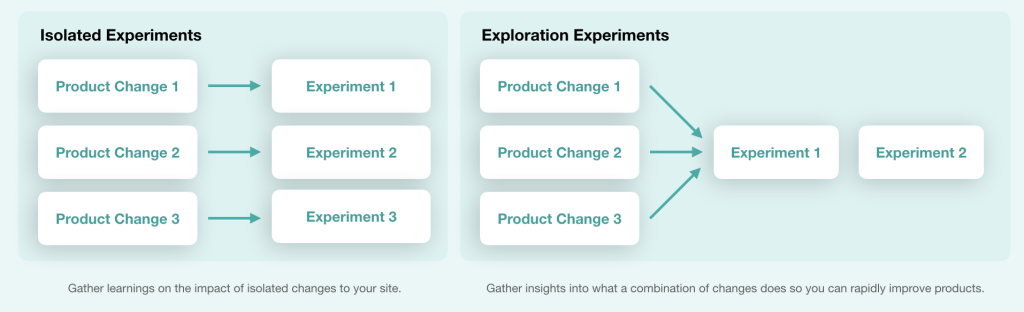
Experimentation for Product instead of Conversion improvements
Over the last years, I’ve had many (healthy) debates with product, brand and growth teams on what experiments to run and for what reason. In some cases, it was easier to run brand or product experiments just like a regular experiment to improve conversion rate. But in the some of them there was fear that […]
Joining RVshare!
I’m joining RVshare, a two-sided marketplace for RVs and motorhomes, as their VP Marketing! Over the last few weeks, I’ve talked extensively with the founders and part of the team. It became clear that this was a great opportunity for a few reasons. Why RVshare? They have great product-market fit and proved this concept clearly […]