Web Analytics Archives
Assigning Purchases to Other Users in Google Analytics UA
Sometimes, you want to assign specific user interactions to a different user. There are many cases where you want to send an event for user X while user Y performs the action. But it’s important that you can save this information to the right user. In our case, we ran into the use case where […]

Part 5: Airflow on Google Cloud Composer – Building a Marketing Data Lake and Data Warehouse on Google Cloud Platform
In the previous blog posts (part 1, part 2, part 3, and part 4) in this series, we talked about why we decided to build a marketing data warehouse. This endeavor started by figuring out how to deal with the first part: making the data lake. In the fourth blog post, a more technical one, […]

Part 4: Visualization with Google DataStudio – Building a Marketing Data Lake and Data Warehouse on Google Cloud Platform
In the previous blog posts (part 1, part 2, and part 3) in this series, we talked about why we decided to build a marketing data warehouse. This endeavor started by figuring out how to deal with the first part: building the data lake. In the fourth blog post, we’ll chat about how we are […]

Part 3: Transforming Into a Data Warehouse – Building a Marketing Data Lake and Data Warehouse on Google Cloud Platform
In the previous blog posts (part 1 and part 2) in this series, we talked about why we decided to build a marketing data warehouse. This endeavor started by figuring out how to deal with the first part: building the data lake. We’ll try to go a bit more into detail on how you can […]

Part 1: Why Build a Marketing Data Warehouse? – Building a Marketing Data Lake and Data Warehouse on Google Cloud Platform
This blog post is part of a series of three, in which we’ll dive into the details of why we wanted to create a data warehouse, how we created the data lake, how we used the data lake to create a data warehouse. It is written with the help of @RickDronkers and @hu_me / MarketLytics, […]

Calculating Click Through Rates for SEO, based on Google Search Console Data (in R)
Updated June 4, 2019: Added a YouTube video which will guide you through the setup process in RStudio and how to run the script yourself. Averages lie & average click-through rates aren’t very helpful! Here I said it. What I do believe in, is that you can calculate click-through rates (CTR) for your own site […]

Adding additional site speed metrics to Google Analytics: measuring First Input Delay (FID)
Web Analytics is still one of my pet peeves, and while I don’t get to spend a ton of time on it anymore these days, I still enjoy digging through blog posts and coming up with new ideas on what to track and how it can help for (speed) optimization. While I was looking through […]

Measuring Content Performance: Content Engagement Metrics
What is the effectiveness of our content, how well does our content work? Who is writing the best content? What should we be writing about next? These were the top X questions I received on a weekly basis while working at The Next Web. And I’m probably not the only one, I hear a lot […]
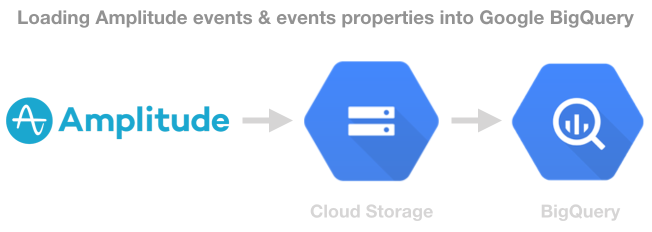
Exporting Amplitude Data to Google BigQuery
I’ve written about using Amplitude before on this blog (in Dutch), but what if you want to combine the huge amount of data that you have in Amplitude with your other big data. The Enterprise version gives you the ability to export your data to a Redshift cluster. But a lot of companies these days are […]
Using Amplitude for Product & Web Analytics
I’ve previously published this blog post in Dutch on Webanalisten.nl. What if you are looking for a product for web analytics but have a lot of events, a complicated product and sending more and more data over time. Sometimes it wouldn’t just work to go with Google Analytics (360), Adobe Analytics and maybe integrating your […]