A few weeks ago I gave a talk at an SEO Meetup in San Francisco. It was a great opportunity to get some more feedback on a product/tool that I’m working on (and that we are already using at Postmates). You’ll hear more on this in the upcoming months (hopefully). In a previous blog post at TNW I talked about using dozens of GBs of data to get better insights in search performance. Over the last years I kept working on the actual code around this to also provide myself with more insights into the world around a set of keywords.
Because billions of searches are done on a daily basis and ~20% of queries haven’t been searched for in the past 30-90 days it means that there is always something new to find out. I’m on the hunt to explore these new keyword areas/segment & opportunities as fast as possible to get an idea on how important they can be.
That means two things:
- The keyword might be absolutely new and has never been searched for.
- The keyword has never come up on the radar of the company, it was never a related keyword or never got an impression simply because content didn’t rank for it.
Usually the next thing you want to know is what their ranking is so you can start improving on it, obviously that can be done in thousands of ways. But hopefully the process would usually work something like this. Moving up from an insane ranking (read: nowhere to be found) to the first position within a dozen weeks (don’t we all wish that can happen in that amount of time?).
Obviously what you’re looking for is hopefully a graph for a keyword that will look something like this:
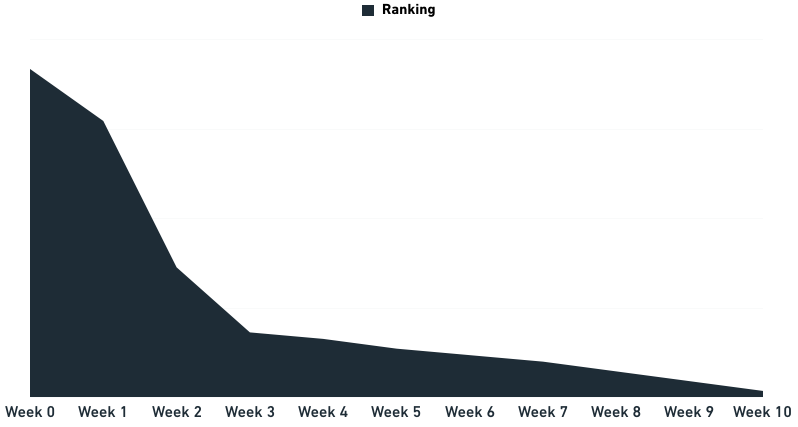
What am I talking about?
Back at TNW my team was tracking 30.000 keywords on a weekly basis to get better insights into what was happening with our search volume & our rankings. It has multiple benefits:
- Get insights into your own performance for specific keywords.
- Get insights in your actual performance in search engines (are 100 keywords increasing/stable/decreasing?).
- Get insights into your competitors performance.
Besides that there is a great opportunity to learn more about the flux/delta of changes in the search results. You’re likely familiar with Mozcast & SERPMetrics Flux and other ‘weather’ radars that monitor the flux in rankings for tons of keywords to see what is changing and if they’re noticing an update. With your own toolset you’ll be able to get insights into that immediately. I started thinking about this whole concept years ago after this Mozcon talk from Martin McDonald in 2013. One of the things that are particularly interesting:
Share of Voice
You’ve also likely heard of the concept of Share of Voice in search. In this case we’re talking about it in the concept of rankings. If you rank #100 in the search results, you’ll get 1 point. If you’ll rank #1 you would assign it 100 points. Which basically means that you will get more points the higher you’ll rank. If you bundle all the keywords together, let’s say 100 you can get: 100 x 100 = 10.000 in total. Over time this will help you to see how a lot of rankings will be influenced and where you’re growing instead of being focused on just the rankings of 1 keyword (always a bad idea in my opinion).
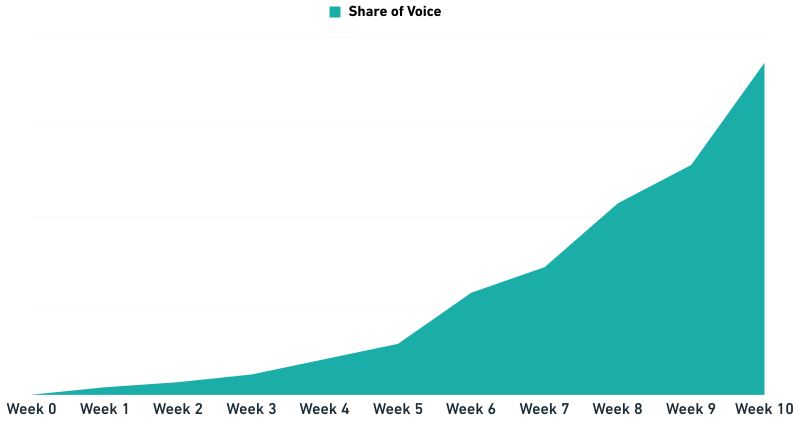
In addition to measuring this for yourself, there will also be other useful ways you can use Share of Voice:
- Who are my competitors: Obviously you know your direct competitors, but most of the times that doesn’t mean that they’re the same as you’re going against in search results. Get the top 10-20-50-100 (whatever works for you) and count the URLs for the same domain in all of the keywords in a group and multiply that by their Share of Voice. The ones that raise to the top will be the competitors that are annoying you most.
- Competitors: You’re familiar now with the concept, so if you apply the same thing to your competitors you’re able to figure out how they’re growing compared to you and what their coverage is in search for a set of keywords. Basically providing you with the data you otherwise would have to dig up somewhere else.
How can you combine it with other data sets?
In a future blog posts I’m hoping to tell you more about how to do the actual work to connect your data to other sets in order for it to make sense. But the heading I’m going for right now is to also look more at competitors/ or at least other people in the same space. There is probably a big overlap with them but there also will be a lot of keywords missing.
What’s next?
I’m nearing the end of the first alpha version to use, it will enable users to track their rankings wherever they want. Don’t dozens of tools already do that? Yes! I’m just trying to make the process more useful for bigger companies and provide users with more opportunities to expand their keyword arsenal. All with the goal to increase innovation in this space and to lower costs. It doesn’t have to be expensive to track thousands of keywords whenever you want.