Thoughts on building marketing & growth capabilities

Learnings from Sales & Marketing Spend of Public Consumer Companies
What percentage of expenses is acceptable to spend on Sales & Marketing: 4% or 52%. What if I told you that both are acceptable answers? Looking at a few dozen public companies (focusing on consumers, knowing that B2B/SaaS dynamics are even more different), I found interesting answers to these questions. The quarterly and yearly earnings […]

Developing Marketing skills & capabilities
Everyone in their career focuses on learning the latest tools or technologies. These rarely change the game as they’re “just” skills. TikTok or Prompt Engineering are platforms and skills but aren’t necessarily capabilities you can be competent in. In the example you just read, understanding TikTok as a platform and the content there helps build […]

Extending our Marketing Data Lake & Warehouse
Marketing Analytics has evolved; it is no longer just ‘web analytics.’ When more marketing budget is spent, you need additional insights that Google Analytics or similar tools can’t offer. That doesn’t mean they have no more reason for existence, but they just become part of a bigger marketing analytics stack instead of relying solely on […]

What books am I reading in 2023?
20 books in 2022 and hundreds of articles (via Pocket)! With me setting a goal last year of >15, I did pretty well. Especially in the first six months of the year, I had a good pace and averaged 2.5 books a month. In the second half, I slowed down and read some larger ones. Why […]
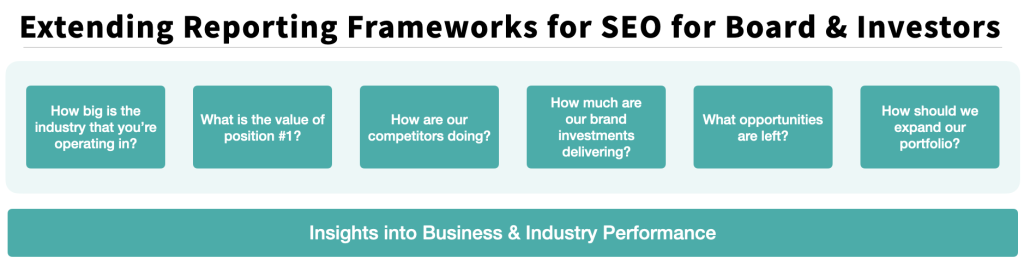
Reporting Frameworks for SEO for Boards & Investors
Since I started to present at board meetings a few years ago, it’s been interesting to understand how board members/investors think about a business/industry. As Marketing, you’re just a tiny piece of the whole puzzle (which was my first humble learning). It is even more important to use your time with them wisely. As marketers […]
The Concept of Input Metrics for SEO
Sessions, transactions, and revenue are not metrics that an SEO shift overnight. It’s a matter of often waiting for Google. They’re considered output metrics, the work that you’ve put in results in those. I just put down the book: Working Backwards by Bill Carr and Colin Bryar. It’s about their many learnings working for years at Amazon. […]
Assigning Purchases to Other Users in Google Analytics UA
Sometimes, you want to assign specific user interactions to a different user. There are many cases where you want to send an event for user X while user Y performs the action. But it’s important that you can save this information to the right user. In our case, we ran into the use case where […]

Learnings from Managing Marketing Budgets
In my 1st job in Marketing, I ‘managed’ a marketing budget of less than €5.000 a month (mainly paid acquisition spend), eventually growing it to about €20.000 a month. My budget responsibility has grown significantly a few jobs later, while I am now responsible for a yearly eight-digit figure ($)💸. This creates a need for […]

Building a data warehouse for SEO in Google BigQuery
Why do you want/need a data warehouse for SEO? A data warehouse (& data lake) stores and structures data (through data pipelines) and then makes it possible to visualize it. That means it can also be used to help create and power your SEO reporting infrastructure, especially when you’re dealing with lots of different data […]
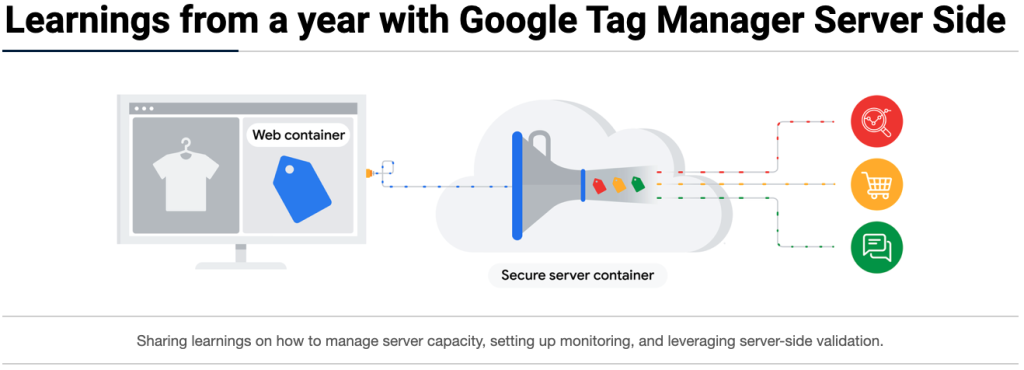
Learnings from a year with Google Tag Manager Server Side
Over the last few years, I’ve written several times about Google Tag Manager, especially when I was at The Next Web as we had an extensive integration. Something we ran into over time was the lack of being able to send events that needed validation or were triggered from the front-end. At the time, I asked the […]