Testing & Optimization Archives
Experimentation for Product instead of Conversion improvements
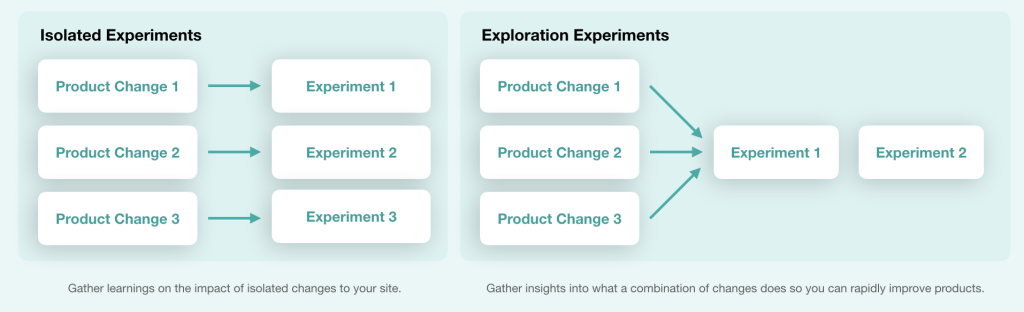
Over the last years, I’ve had many (healthy) debates with product, brand and growth teams on what experiments to run and for what reason. In some cases, it was easier to run brand or product experiments just like a regular experiment to improve conversion rate. But in the some of them there was fear that […]
20 Reasons Why Most Experiment Programs Are Setup for Failure
Over the course of the last few years I worked on over 200+ experiments, from a simple change to a Call To Action (CTA) up to complete design overhauls and full feature integrations into products. So far it taught me a lot about how to set up an experiment program and what you can mess […]