20 Reasons Why Most Experiment Programs Are Setup for Failure
By Martijn Scheijbeler Published November 7, 2017Over the course of the last few years I worked on over 200+ experiments, from a simple change to a Call To Action (CTA) up to complete design overhauls and full feature integrations into products. So far it taught me a lot about how to set up an experiment program and what you can mess up along the way that could have a major impact (good and/or bad). As I get a lot of questions these days on how to set up a new testing program or people asking me how to get started I created a slide deck that I gave a couple times this year at conferences about all the failures that I see & made myself running an experimentation program.
The (well known) process of A/B Testing
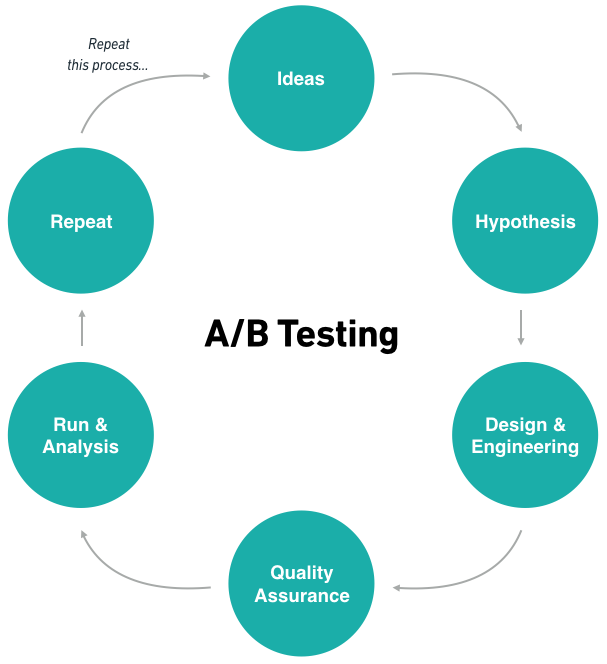
You’ve all seen this ‘circle’ process before. It shows the different stages of an experiment, you start with a ton of ideas, you create their hypothesis, you go on to designing & building them (with or without engineers), you do the appropriate Quality Assurance checks before launching, you run an analyze the results of your test. If all goes well you’re able to repeat this process endlessly. Sounds relatively easy, right? It could be, although along the way I’ve made mistakes in all of these steps. In this blog post I’d like to run you through the top 20 mistakes that I’ve (seen being) made.
You can also go through the slidedeck that I’ve presented at LAUNCH SCALE and Growth Marketing Conference:
Ideas
1. They just launch, they just test.
One of the easiest to spot mistakes, as you’re basically not experimenting but putting features/products live without figuring out if they’re really going to have an impact on what you’re doing. That’s why you basically always want to give a certain feature a test run on a small percentage of your traffic, if your audience is big enough that could be just as little as 1% or for smaller companies run it 50%/%50. In that case it’s easier for you to isolate what the impact is, that’s the solution to this problem.
2. Companies that believe they’re wasting money with experimentation.
One of the most fun arguments to run into in my opinion. Whenever organisations think that by running so many experiments that don’t provide a winner it might kill their bottom line there are still some steps to take that will help them better understand experimentation. Most of the times this is easy to over come, ask them what they think the right way to go is with experimentation and let them pick the winners for a few experiments. Chances are about 100% that at least one of their answers will be proven wrong. Point being that whenever they would have made the decision based on gut feeling or experience it also would cost the organization money (and in most cases even way more money). That’s why it’s still important to quickly overcome this argument and get the buy-in of the whole organization to make sure people believe in experimentation.
3. Expect Big Wins.
It depends in what stage you are with your experimentation program, at the beginning it’s likely that you’ll pick up a lot of low hanging fruit that will provide you with some easy wins. But I promise it won’t get easier of time (read more about the local maximum here). You won’t be achieving big results all the time. But don’t give up, if you can still achieve a lot of small wins over time it will also sum up to a lot of results. If you expect that every test will double your business as you might read in (bad) blog posts, you won’t.
4. My Competitor is Doing X, so that’s why we’re testing X.
Wrong! Chances are your competitor also has no clue what they’re doing, just like you! So focus on what you should be doing best, know your own customers and focus on your own success. Even when you see your competition is running experiments, chances are high that they’re also not sure what will become a winner and what will be a loser. So focusing on repeating their success will only put you behind them as you need to spend maybe even longer then them figuring out what’s working and what’s not.
5. Running tests when you don’t have (enough) traffic.
Probably the most asked question around experimentation: How much traffic do I need to run a successful experiment on my site? Usually followed by: I don’t have that much traffic, should I still be focused on running experiments. What I’d recommend most of the time is figure out if you can successfully launch more than ~20 experiments yearly. If you have to wait too long on results for your experiments you might run into trouble with your analysis (see one of the items on this laster). This is combined most of the time with the fact that these teams are relatively small and don’t always have the capacity to do more with this it might be better to focus first on converting more users or focus on the top of the funnel (acquisition).
Hypothesis
6. They don’t create a hypothesis.
I can’t explain writing a hypothesis better than this blog post by Craig Sullivan. Where he lays out the frameworks for a simple and more advanced hypothesis. If you don’t have a hypothesis, you can’t use it to verify later on that your test has been successful or not. That’s why you want to make sure that you have documented how you are going to measure the impact and how you’ll be evaluating that the impact was big enough that you’ll deploy it.
7. Testing multiple variables at the same time, 3 changes require 3 tests.
Great, you realize that you need to test more. That’s a good step in the right direction. But over time changing too many elements on a specific page or across pages can make it hard to figure out what is leading to an actual change in results for an experiment. But if you need to show real results in an experiment you could turn this failure into a winner by running 1 experiment where you change a lot and seeing what the impact is. Which after you do you run more experiments that will prove what specific element brought most of the value. I’d like to do this from time to time, sometimes when you make small incremental changes time after time it could be that there is no clear winner. Running a big experiment will help in that case to see if you can impact the results with that. Once you do that, go back and experiment with smaller changes to see what exactly led to that result so you know going forward what potential areas are for experimentation that will provide big changes.
8. Use numbers as the basis of your research, not your gut feeling.
We like our green buttons more than our red ones. In the early days of experimentation an often heard reply. These days I still hear many variations of the same line. But what you want to make sure is that you use data as the basis for your experiment instead of a gut feeling. If you know based on research that you need to improve the submission rate for a form. You usually won’t be asking more questions but want to make sure that the flow of the form is getting more optimal to boost results. If you noticed in your heat maps or surveys that users are clicking in a certain area or can’t find the answer on a particular question they have you might want to add more buttons or a FAQ. By adding and testing you’re building on top of a hypothesis, like we discussed, before that is data driven.
Design & Engineering
9. Before and After is not an A/B test. We launched, let’s see what the impact is.
The most dangerous way of testing that I see companies do is testing: before > after. You’re testing what the impact is of a certain change by just launching it, which is dangerous considering that many surrounding factors are changing with that as well. With experiments like this it’s near impossible to really isolate the impact on the change, making it basically not an experiment but just a change where you’re hoping to see what the impact is.
10. They go over 71616 revisions for the design.
You want to follow your brand and design guidelines, I get that. It’s important as you don’t want to run something that is not going to open up to the world if it’s a winner. But if you’re trying to figure out what the perfect design solution is to a problem you’re probably wasting your time as that’s exactly why you’re running an experiment, to find the actual best variant. That’s why I would advise to come up with a couple of design ideas that you can experiment with and run the test as soon as possible to learn and adapt to the results as soon as possible.
Quality Assurance
11. They don’t Q&A their tests. Even your mother can have an opinion this time.
Most of the time your mother shouldn’t be playing a role in your testing program. The chances that she can tell you more about two tiered tests and how you should be interpreting your results then you do as an upcoming testing expert are very minimal. But what she can help you with is make sure that your tests are functionally working. Just make sure she’s segmented in your new variant and run her through the flow of your test. Is everything working as expected? Is nothing breaking? Does your code work in all browsers and across devices? With more complex tests I noticed that usually at least 1 element when you put it through some extensive testing, that’s why this step is so important in your program. Every test that is not working can be a waste of testing days in the years and one not spend on actually optimizing for positive returns.
Run & Analysis
12. Running your tests not long enough, calling the results early.
Technically you can run your test for 1 hour and achieve significance if you had the right amount of users + conversions in your tests. But that doesn’t always mean you should call the results of the test. A lot of business deal with longer lead/sales times which could influence the results, also weekends, weekdays whatever can influence your business is something that might have your results be different. You want to take all of this into account to make sure your results are as trustworthy as possible.

13. Running multiple tests with overlap.. it’s possible, but segment the sh*t out of your tests.
If you have the traffic to run multiple experiments at the same time you’ll likely run into the issue that your tests will overlap. If you run a test on the homepage and at the same time one on your product pages it’s likely that a user might end up in both experiments at the same time. Most people don’t realize that this is influencing the results of the experiment for both tests as theoretically you just ended running a Multivariate test across multiple pages. That’s why it’s important to also use this in your analysis, by creating the right segments where you audience is overlapping in multiple experiments but also by isolating the users in 1 segment.
14. Data is not sent to your main analytics tool, or you’re comparing your A/B testing tool to analytics, good luck.
You’re likely already using a tool for your Web Analytics; Google Analytics, Clicky, Adobe Analytics, Omniture, Amplitude, etc.. chances are that they’re tracking the core metrics that matter to your business. As most A/B testing tools are also measuring similar metrics that are relevant for your tests you’ll likely run into a discrepancy between the metrics, either on revenue (sales, revenue, conversion rate) or regular visitor metrics (clicks, session, users). They’re loading before/after your main analytics tool and/or the definition of the metrics are different, that’s why you’ll always end up with some difference that can’t be explained. What I usually tried was making sure that all the information on an experiment is also captured in your main analytics tool (GA was usually the tool of my liking). Then you don’t have to worry about any discrepancies as you’re using your main analytics tool (which should be tracking everything related to your business) to analyze the impact of an experiment.
15. Going with your results without significance.
Your results are improving with 10% but the significance is only 75%. That’s a problem, it means that 25% of the time you don’t know for sure that the experiment is going to provide the results that you have so far (although you still would never know for sure as reaching 100% is impossible). With experimentation it’s a problem, in simple words: it basically means that you can’t trust the results of your experiment as they aren’t significant enough to say it’s a winner or a loser just yet. When you want to know if your results are significant make sure that you’re using a tool that can calculate this for you, one of these tools is this significance calculator. You enter the data from your experiment and you’ll find out what the impact was.
16. You run your tests for too long… more than 4 weeks is not to be advised, cookie deletion.
For smaller sites that don’t have a ton of traffic it can be hard to reach significance, they just need a lot of data to make a decision that is supported by it. But also for smaller sites that are running experiments on a smaller segment this could become an issue. If your test is running for multiple weeks, let’s say 4+ weeks, it’s going to be hard to measure the impact for this in a realistic way as it could be that people are deleting their cookies and a lot of surrounding variables might be changing during that period of time. What that means is that over time the context of the experiment might change too much which could have an effect on how you’re analyzing the results.
Repeat

17. Not deploying your winner fast enough, it takes 2 months to launch.
One of the aspects of experimentation is that you have to move fast (and not break things). When you find a winning variant in your experiment you want to have the benefits from it as soon as possible. That’s how you make a testing program worth it for your business. Too often I see companies (usually the bigger ones) having to deal with the rough implementation process to get something implemented for production purposes. A great failure because they can’t get the upside of the experiment and likely by the time they can finally launch the winning variant circumstances have changed so much that it might already need a re-test.
18. They’re not keeping track of their tests. No documentation.
Can you tell me what the variants looked like of the test that ran two months ago and what the significance level was for that specific test? You probably can’t as you didn’t keep track of your testing documentation. Definitely in bigger organizations and when you’re company is testing with multiple teams at the same time this is a big issue. As you’re collecting so many learnings over time it can be super valuable to keep track of them, so document what you’re doing. You don’t want to make the mistake that another team is implementing a clear loser that you’ve tested months ago. You want to prove to them that you’ve already ran the test before. Your testing documentation will help you with that, in addition it can be very helpful in organizing the numbers. If you want to know what you’ve optimized on a certain page it can probably tell you over time changing what elements brought most return.
19. They’re not retesting their previous ideas.
You tested something 5 months ago, but as so many variables changed it might be time to come up a new experiment that is re-testing your original evaluation. This also goes for experiments that did provide a clear winner, over time you still want to know if the uplift that noticed before is still going on or if the results have flattened over time. A retest is great for this as you’re testing your original hypothesis again to see what has been changed. It will provide you usually with even more learnings.
20. They give up.
Never give up, there is so much to learn about your audience when you keep on testing. You’ve never reached the limits! Keep on going whenever a new experiment doesn’t provide a new winner. The compound effect: incremental improvements is what lets most companies win!

That’s it, please don’t make all these mistakes anymore! I already made them for you..
What did I miss, what kind of failures did you have while setting up your experimentation program and what did you learn from them?