Case Study: How Restructuring 6800 Content Pieces For SEO Worked
By Martijn Scheijbeler Published June 16, 2020 Last Modified January 11, 2023I presented the content in this blog post about a week ago for the Traffic Think Tank community (highly recommend it), but after a Twitter thread on this topic as well, it’s time to turn it into a blog post.
Sometimes you have to take a stand and make something better when it’s already performing well. Over the last months, the RVshare marketing team worked on some great projects; one of them that I was involved in was restructuring 6800 pieces of content that we created a while ago. The content and pages they were on were performing outstanding (growing +100% YOY without any real effort), but we wanted to do more, to help users and boost SEO traffic. So we got started…
Why restructure content?
A couple of years ago, we published the last WordPress page/post in a series of 600+, the intent: go after a category near and dear to the core of the RVshare business: help more people rent an RV. We did that by creating tons of articles specifically for cities/areas. Now over two and a half years later, the content is driving millions of people yearly, mainly from SEO, but we knew that there was more as it’s not our core business. We also weren’t leveraging all the SEO features that have become available since two years ago, think about additional structured data like FAQs but also monetization that we thought was important. All improvements that we had to go back into every post for if we wanted to take advantage of it.
What we did, leveraging Mechanical Turk.
One of the biggest obstacles wasn’t necessarily rebuilding pages, coming up with a better design, etc. WE have a great team that is nailing this on a daily basis. But having to deal with 650 posts that contained ten sub-elements itself was a struggle. The content was structured in a similar way but some quick proof of concepts identified that scraping wasn’t the solution as the error ratio was way too high as with most projects we wanted to ensure that the content could be restructured at low costs not to avoid this project not having a valid business case (does the actual opportunity outweigh the potential costs to restructure the content?).
Scraping versus Mechanical Turk
As we had initially structured the content the same way: headline, description, etc. we were able to have at least a way to get the data out. When we did some testing to see if we would be able to scrape it looked unfortunate, there were too many edge cases as the HTML itself around it was barely structured enough to get the actual content out of it.
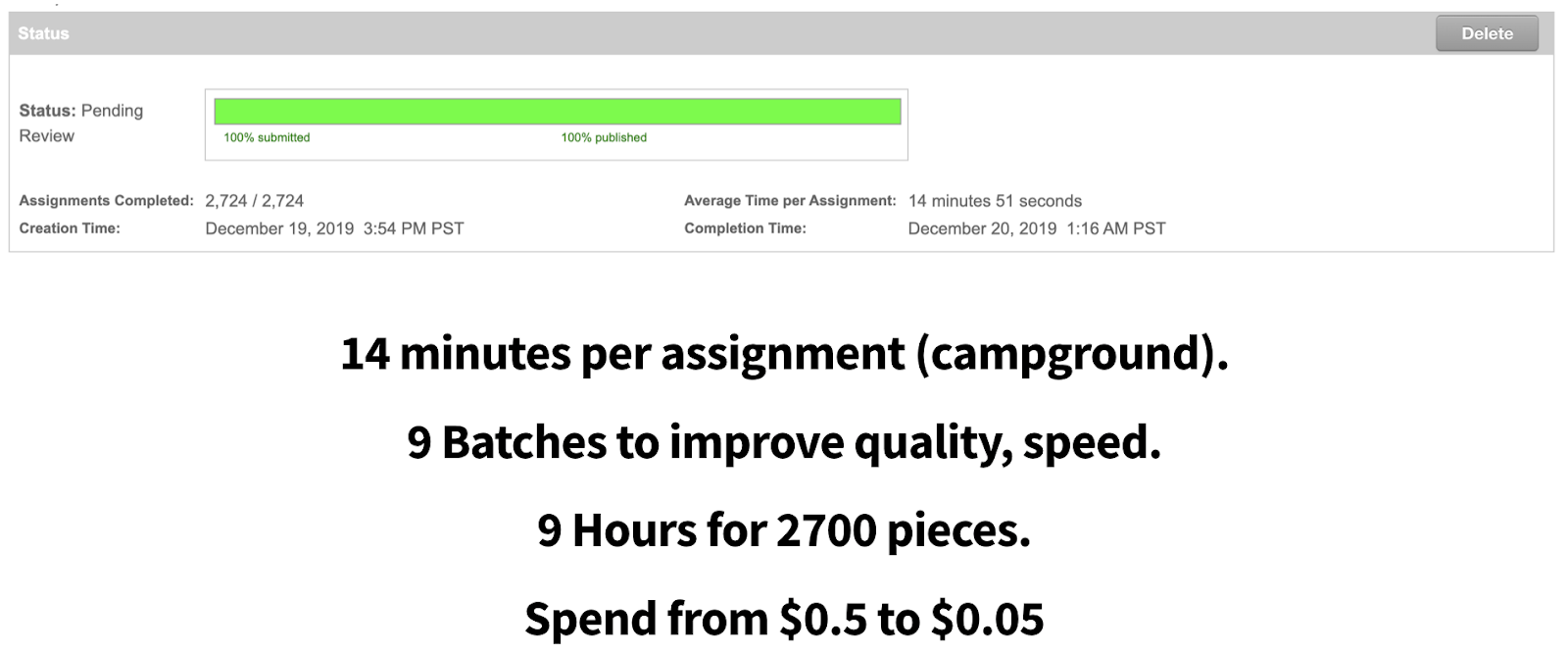
We looked into Mechanical Turk as the second option as it gave us the ability to quickly get thousands of people on a task to look at the content and take out what we needed. We wrote the briefing, divided the project in a few chunks, and within 10-12 hours, we had the content individualized per piece. We did our best to deal with most of the data cleaning from the workers directly in the briefing and form but also had some cleaning scripts ready. After it was cleaned, we imported the data into our headless CMS Prismic.
How to do this yourself?
- Create an account on Mechanical Turk.
- Create a project focused around content extraction.
- Identify what kind of content you want individualized, it works best if there is a current structure (list format, table) that can be followed by the Turks. This way, you can tell them to pick up content piece X, Y, Z, for a specific URL.
- Identify the fields that you want to be copied.
- Upload a list of URLs that you want them to cover and additionally the # that it has on the list.
- Start the project and verify the results.
- Upload the data automatically back into your CMS (we used a script that could directly put the content as a batch into our headless CMS Prismic.io)

Rebuilding
We decided to build the content from the ground up, which meant:
- Build out category pages with the top content pieces by state.
- Build out the main index page with the top content from all states.
- Build the ability to showcase this content on all of our other templated pages across RVshare.
By building out the specific templates, it gave us additional power to streamline internal linking, create better internal relevance, build-out structured data but mainly figure out a right way on how to leverage a headless CMS with all its capabilities instead of just having raw (read: ‘dumb’) content that can’t be appropriately structured. We already use the headless CMS Prismic.io to do this, in which you can create custom post types, as you see in this screenshot. You define the custom post type and can pick the kind of fields that you want, which turns itself just another CMS after that. The content can then be leveraged through their API.
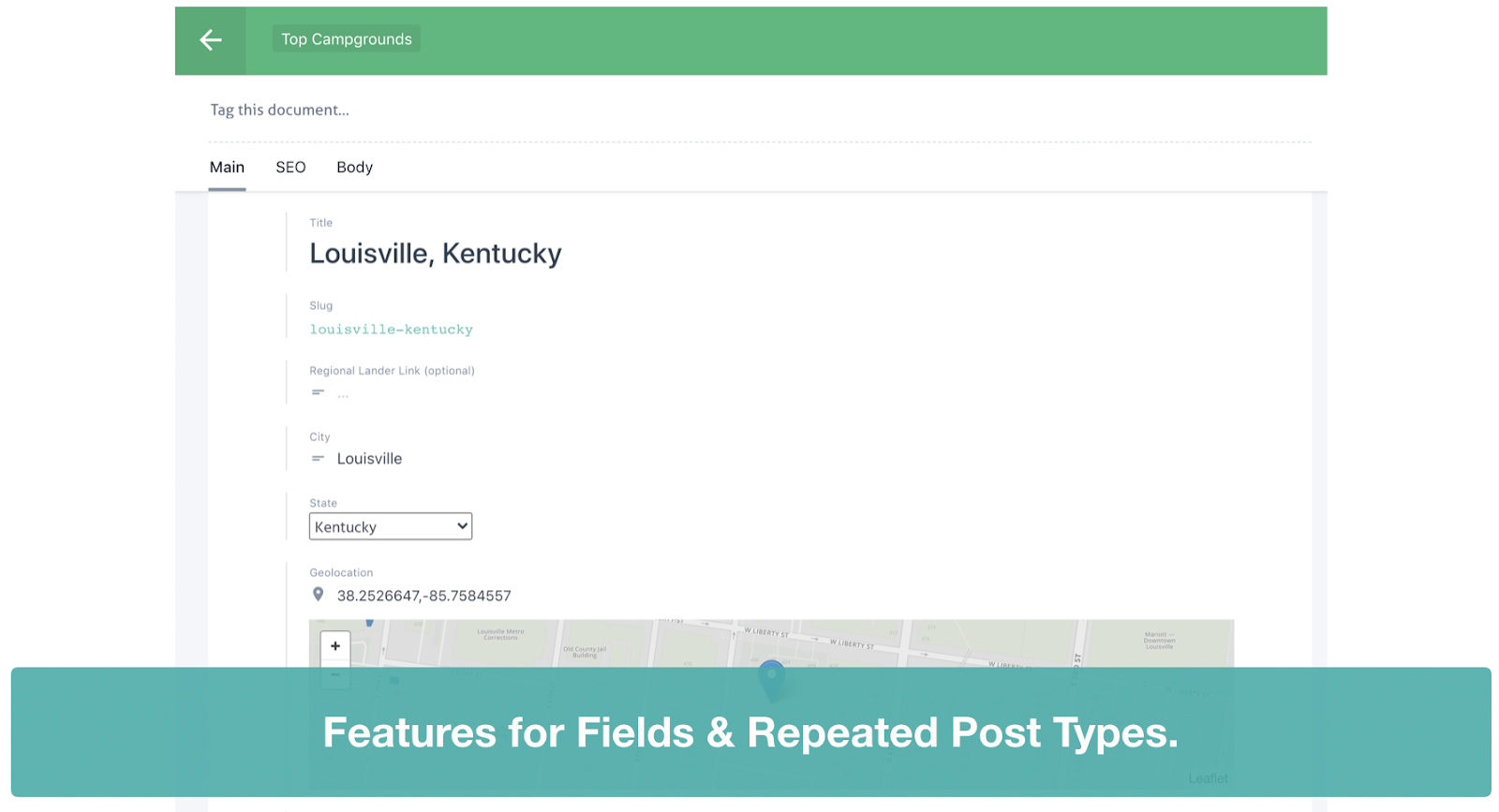
How to do this yourself?
We were previously leveraging WordPress ourselves, but all entities were saved as 1 post. If you’re able to do this differently and save pieces individually it’s many times easier to create overview pages by using categories (and/or tags). This is not right away something that you can always do without development support.
Results
Because of the design changes, engagement increased with over 25% because of the new format. Monetization is making it more interesting to keep on iterating on the results. Sessions were unfortunately really hard to measure we launched the integrations a few weeks prior to the kick-off of COVID-19 resulting in a downwards spiral and a surge in demand right after. Hopefully, in the long-term, we’ll be able to tell more about this. We are sure though that we didn’t suffer on SEO results.
Want to see the new structure of the pages? You can find it here as our effort on the top 10 campgrounds across the United States.